Bias và variance trong mô hình tuyến tính
Bias và variance trong mô hình tuyến tính
Tóm tắt về bias và variance tradeoff trong mô hình tuyến tính
Đây là một bài viết khá hay của tác giả Nischal M ở đây link. Mình xin dịch lại và nhận xét thêm một số thứ.
Chắc hẳn nhiều người đã từng nhìn thấy sơ đồ này:
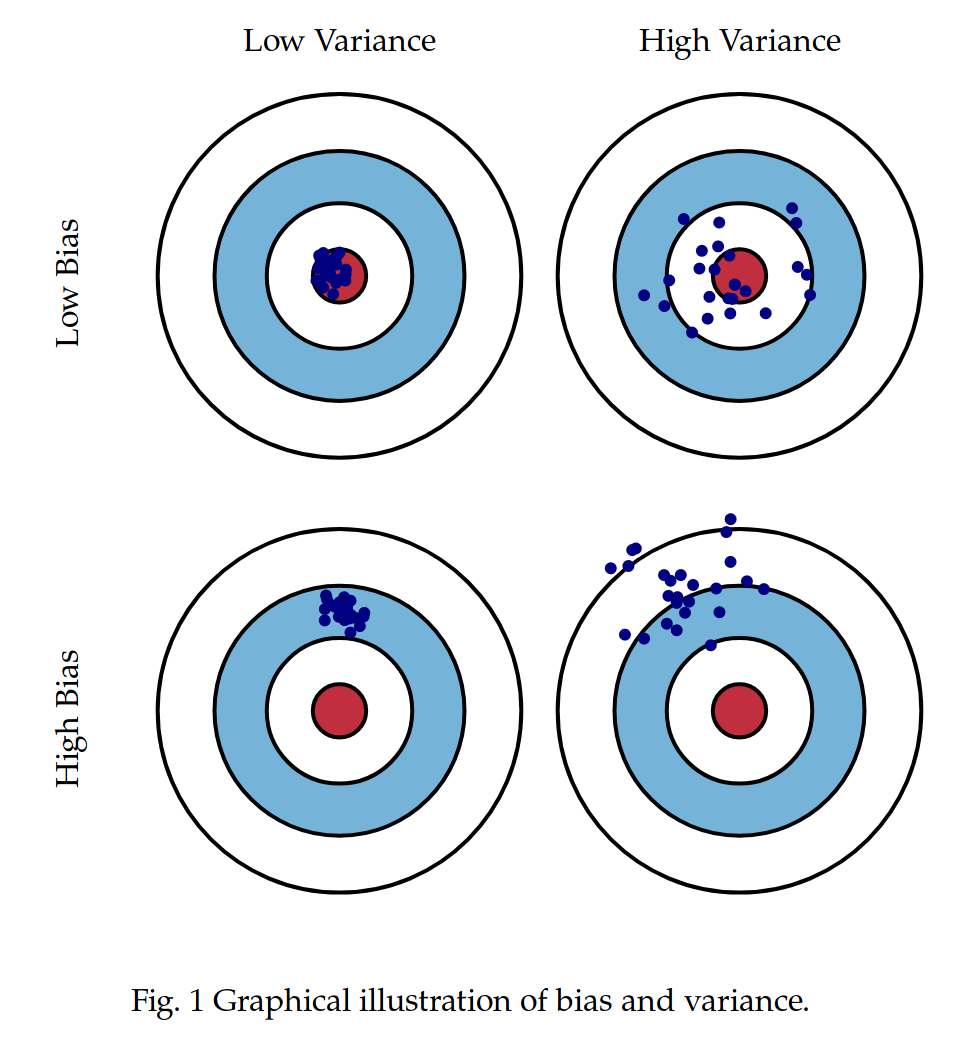
Hình trên cho ta thấy giá trị dự đoán của mô hình với các giá trị bias và variance khác nhau. Hồng tâm của từng tấm bia là label thực tế của dữ liệu và những chấm xanh trên từng hình là giá trị mà mô hình dự đoán ra. Trong bài này, chúng ta sẽ thử trực quan hóa sự trade off giữa bias và variance trong mô hình tuyến tính.
Lí do chọn mô hình tuyến tính để trực quan là vì chúng dễ hiểu và cũng khá dễ dàng để kiểm soát giữa bias và variance thông qua regularization. So với các mô hình phi tuyến, các mô hình OLS (Ordinary Least Squares) regression cũng cho kết quả ít bias và variance thấp hơn. Các mô hình Ridge (OLS với L2 penalty) và Lasso (OLS with L1 penalty) thậm chí còn ít variance hơn so với OLS. Ta có thể kiểm soát mức độ penalty thông qua hệ sốregulariztion, thường gọi là λ. Lasso khá đặc biệt vì nó còn có khả năng zero hóa các hệ số, khá giúp ích trong việc feature extraction.
Thí nghiệm
- Tạo 500 điểm dữ liệu theo phương trình \(y = α+ βx + ϵ\) với \(ϵ \sim N(0, 8)\), \(x \sim U(-2, 2), α = 2\) và \(β = 3\).
- Lặp lại bước 1 \(1000\) lần ta có 1000 tập dữ liệu.
- Đối với mỗi tập fit các mô hình OLS, Ridge và Lasso với một hệ số λ cố định. Sau đó dự đoán \(y\) khi cho \(x = 3\). Kết quả dự đoán nên xấp xỉ \(2 + 3 \times 3 = 11\).
Bây giờ ta có 3000 = (1000 OLS + 1000 Ridge + 1000 Lasso) giá trị \(x\) dự đoán. Dựa vào các giá trị dự đoán này, ta đã đủ thông tin để có chơi với các mô hình và khảo sát các tính chất của chúng 😃.
\(λ \sim 0\)
Với giá trị λ rất nhỏ, tức là gần như không có regularization trong trường hợp này. Do đó ta kì vọng kết quả của 3 mô hình là gần như nhau.
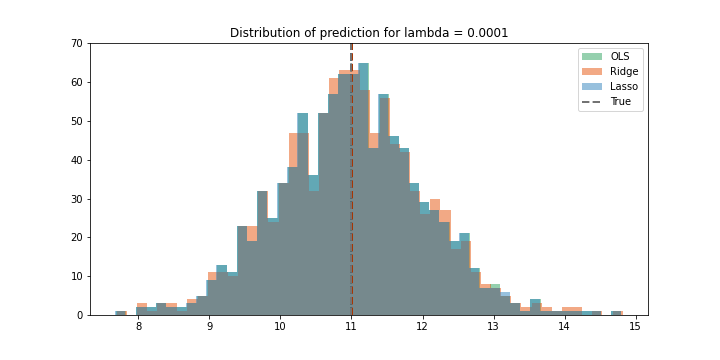
Trong hình, giá trị thực được biểu diễn bằng đường nét đứt màu đen, các giá trị mean của các phân phối cũng là các đường nét đứt nhưng có màu như được chú thich trên bảng.
Ta có thể thấy 3 phân phối overlap lên nhau với giá trị mean xung quanh giá trị thực (là \(x = 2\)). Do đó trường hợp này không có bias, tuy nhiên giá trị variance là lớn (khoảng từ 9 đến 13).
\(λ = 0.01\)
Mới chỉ tăng λ lên một chút ta đã thấy có sự khác biệt ở đây. Theo đó, các phân phối có xu hướng bị dịch sang trái. Ridge bị một ít bias (độ lệch của mean phân phối so với giá trị thực), trong khi Lasso bị bias nhiều hơn. Điều đó cho thấy Lasso nhạy cảm với nhiễu nhiều hơn so với Ridge. Ở trường hợp này variance không thay đổi nhiều so với trường hợp trước.
\(λ = 0.05\)
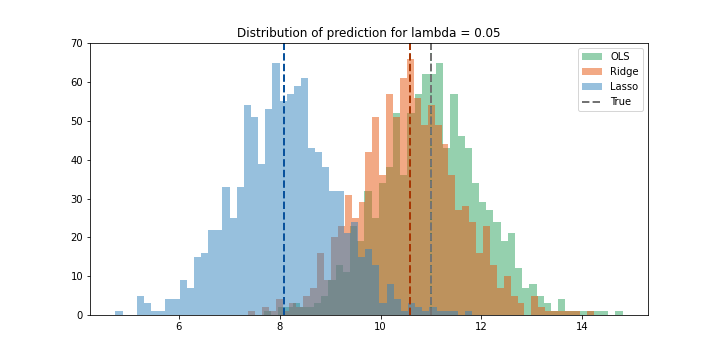
Với λ = 0.05 ta thấy Lasso đã bị bias quá nhiều (3 đơn vị). Ridge vẫn không bị bias nhiều tuy nhiên variance vẫn vậy. Do đó có thể thấy với dữ liệu này thì Ridge không có tác dụng gì.
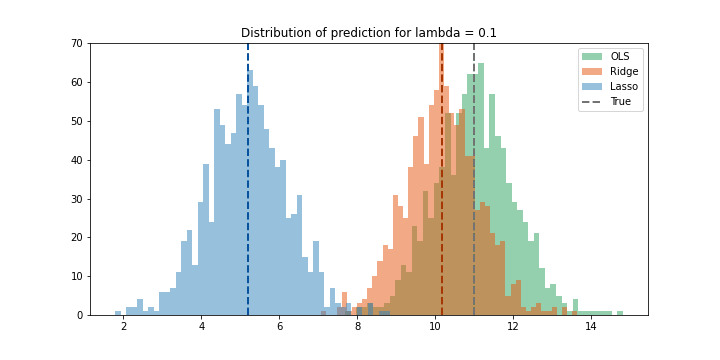
\(λ = 0.1\)
Gần như giống hệt kết quả của trường hợp trước. Ta không thấy rõ sự thay đổi của variance.
\(λ = 0.5\)
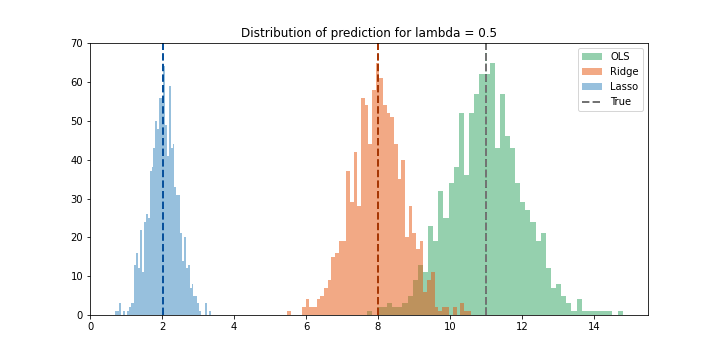
λ cao hơn cho ta một số nhận xét hợp lý sau. Bias của Ridge đã tăng lên gần ba đơn vị, nhưng variance đã nhỏ hơn. Lasso đã penalty làm cho hệ sốβ gần bằng không dẫn đến kết quả có bias rất cao nhưng có variance nhỏ.
\(λ = 1\)
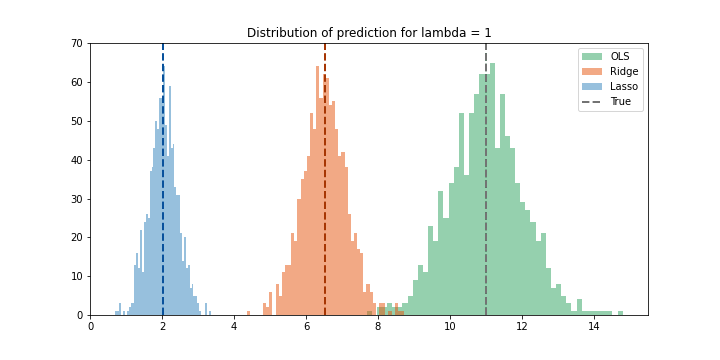
Một kết quả khá ổn. Ở đây sự tradeoff đã đổi chiều. Variance của Ridge đã nhỏ đi đánh đổi với việc có bias lớn.
\(λ = 5\)
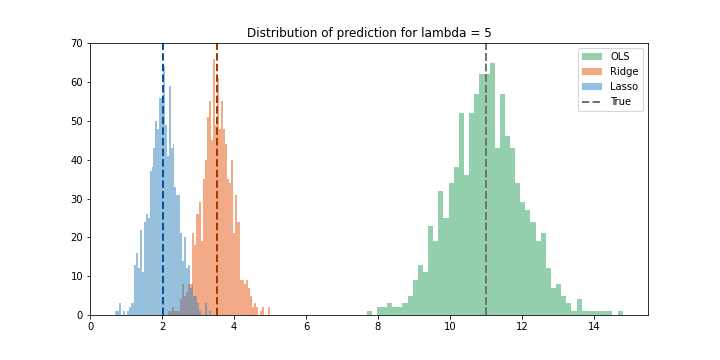
Cuối cùng, ta set λ rất lớn. Variance của Ridge đã trờ nên rất nhỏ, đồng thời bias rất lớn. Trong thực tế ta sẽ không bao giờ cho regularization lớn như vậy, tuy nhiên ở đây có thể thấy rõ sự tradeoff là variance càng nhỏ thì bias càng lớn.
Nhận xét
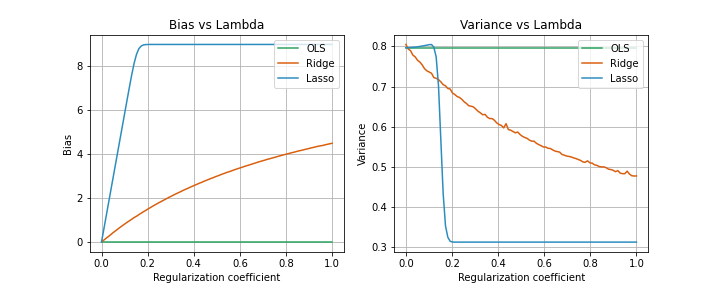
Hình trên cho ta cái nhìn tóm tắt về quá trình thí nghiệm. OLS có bias thấp nhất những cũng variance cao nhất. Ridge có vẻ smooth hơn còn Lasso thì kịch khung cmnr khi λ = 0.2. Theo hình thì Ridge sẽ đạt được sự cân bằng tốt nhất trong tradeoff giữa bias và variance.
Phân phối lý tưởng:
Một phân phối lý tưởng trong thực tế sẽ có dạng như sau:
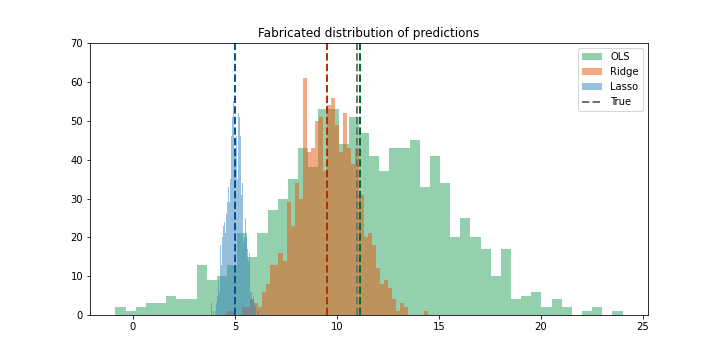
Lợi thế mà Ridge cung cấp ngay lập tức được thể hiện rõ ràng ở đây. Ridge đưa ra dự đoán hơi bias, nhưng sẽ đưa ra dự đoán gần với giá trị thực thường xuyên hơn so với OLS. Đây là giá trị thực sự của Ridge. Một sự bias nhỏ, nhưng dự đoán nhất quán hơn. OLS đưa ra kết quả không bias nhưng không nhất quán. OLS cho kết quả trung bình không bias, tuy nhiên kết quả ở từng điểm dữ liệu thì không phải lúc nào cũng vậy. Và đó là sự tradeoff giữa bias và variance hình thành trong các mô hình tuyến tính.